2017年8月15日掲載
数年前から、AI(Artificial Intelligence、人工知能)が一般の人の話題にも上るようになり、ブームと言える状況になりました。しかし、なぜ突然ブームになったのか、現状では何ができるのか明確な人はあまりいないようです。
そこで前回から3回にわたって、AIの歴史、ここ数年間の動向、そして近い将来を中心にAIの未来像について解説しています。今回はAIのここ数年間の動向についてです。

ITコンサルタントの美咲いずみ(仮名)は、東京都港区にあるスマイルソフト(仮名)の神谷隆介(仮名)社長から、月1回経営のためのIT活用の相談を受けている。スマイルソフトは、中堅企業向けのCRM(顧客管理システム)パッケージソフトKIZUNA(仮称)の開発・販売で急成長した、IPO準備中の新興企業だ。
相談したいテーマは神谷社長から事前に送ることになっている。今回は「AIについて」だった。
いずみは、AIの定義や歴史、またAIの判定法など(第33回ご参照)について話したあと、いったん休憩し話を再開した。
いずみが言う。
「先ほど、AIの第3次ブームは2012年の『Googleのネコ』がきっかけと申しました。もちろん突然『Googleのネコ』が登場したわけではなく、第2次ブーム以降も続いてきた技術的な積み重ねがあってのことですが、しかし、再ブームを巻き起こすほど『Googleのネコ』は衝撃的だったのです」
「何がそれほどすごかったのですか?」と神谷が尋ねる。
「Googleと言えば世界でも最高峰の検索技術を持っている企業ですので、Googleがネコ画像の認識に成功したと聞いたとき、多くの人はパターン認識の話だと思ったのです。要するに画像のパターンをデータベースに保持しておき、それを高速に探し出すアルゴリズム(解法あるいは処理法)を発見したのだと」
文字解析や音声解析の世界では、AIを使わなくとも膨大なパターンから文字や音声を高い確率で特定する技術が既に存在していた。だが画像のパターン認識は難しく、芳しい成功事例はなかった。当初、Googleがその方法を見つけだしたと誤解した人も多かったのである。
しかし実際には違っていて、これはニューラルネットワーク(後述)による独学だった。
「なるほど。コンピューターが、まるで子どもが自分で学習したかのように、ネコの画像が分かるようになったと言うことだったんですね。それは、すごいし、何だか怖いですよね」と神谷。
「はい。すごいと怖いの両方の意味で、衝撃的だったのです」
神谷が尋ねる。「『Googleのネコ』で用いていた技術はどんなものなのですか?」
「機械学習(マシーンラーニング)の一種で、ディープラーニング(深層学習)と呼ばれるものです。AIには前回出てきたようなエキスパートシステムと言うようなものもありますが、現在の主流は機械学習です。その機械学習の中にニューラルネットワーク(NN)と言う技術があり、ニューラルネットワークの中にディープラーニングと言う技術があります(図1)」
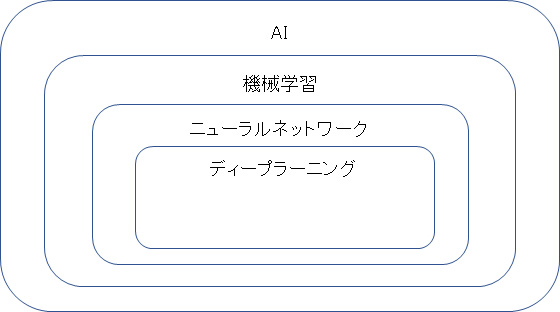
図1:AI、機械学習、ニューラルネットワークおよびディープラーニングの関係。ただし、幾何学に例えると正三角形は二等辺三角形の一種だが、一般に「二等辺三角形」と言えば「正三角形以外の二等辺三角形」を指す。それと同じように、「機械学習」と言えば「ディープラーニング以外の機械学習」を指すことが普通である。なお、「機械学習」は日本語で、「ディープラーニング」は横文字で呼ぶ人が多く、本稿でもそうした。
「では、機械学習について説明いたします」といずみ。
我々はどうやってものを識別するのだろうか? それは多数の「特徴」を捉えているのだと言える。例えば、「赤い」だけだとイチゴ、トマト、郵便ポストなど多くの候補が存在するが、それに表面がつるつるで、緑色のヘタがあり、味は甘酸っぱいとなるとトマトに絞られてくる。
初期の人工知能では、「特徴」を人間が登録していた。しかし登録が大変であるため(上記では例として簡単にトマトの特徴を述べたが、実際には熟れる前の緑のトマトもあるし、トマトの種や芽もある)、特徴の登録を機械自身にさせる、すなわち自動化すると言う発想が出てきた。これが機械学習である。
具体的には、大量の学習用データ(ビッグデータ)をプログラムに読み込ませて、「特徴量」と言うものを計算する。特徴量は数字の羅列(ベクトル)であり、その計算にはさまざまな統計学的手法を用いている。
煩雑で時間のかかる「特徴」の登録作業がなくなったこと、クラウドやSNSの進展などでビッグデータを以前より容易に集められるようになったこと、およびハードウェアの性能向上や大量データの処理技術などビッグデータを処理する環境が整ったことなどが、第3次AIブームが訪れた要因だと言っていいだろう。
なお、機械学習には、「教師あり学習」と「教師なし学習」とがある。これは、学習用データにラベル(人間=教師が付加する正解データ)をつけるか、つけないかの違いである。
例えば「手書き文字認識」のように正解があることについての学習は「教師あり学習」が効率的だ。しかし、膨大なデータから未知の傾向を探る「データマイニング」のような手法では、「教師なし学習」のほうが効率的である。
「続いて、ニューラルネットワーク(図2)について説明いたしましょう。
ニューラルネットワークとは、ひと言で言えば人間の脳を模したコンピューターのことです。
人間の脳にはニューロン(神経細胞)があり、それらが複雑に連携しあって思考や判断をします。図2で言えば●がニューロン(ノードとも言う)に該当します。ニューロン同士でデータの入出力を繰り返すことにより、高速に特徴量が計算できると言う仕組みです」
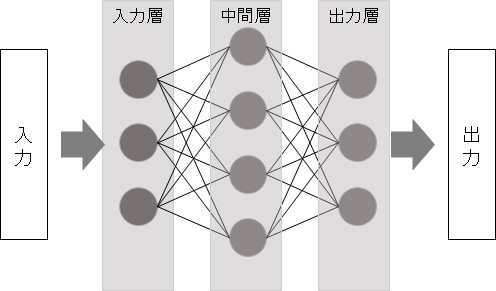
図2:ニューラルネットワーク
ニューラルネットワークのもっとも単純な形態は中間層がなく、入力層と出力層が直結しているものである。たが、それではあまり複雑な処理はできない。
複雑な処理をしようと思うと、中間層を複数階層持たせることになる。この複数の「深い」中間層を持つニューラルネットワークでの機械学習をディープラーニングと呼ぶ。
なお、ニューラルネットワークを利用した機械学習のほとんどはディープラーニングであり、ニューラルネットワーク(NN)と言う言葉が出てくるときは、その形態と特徴を示すことが普通である。具体的には、CNN(畳み込み型ニューラルネットワーク、静止画像の処理に強い)やRNN(再帰型ニューラルネットワーク、動画の処理に強い)などがある。
例えば、「Googleのネコ」は「CNNによるディープラーニング」で実現された。
2016年に囲碁の世界チャンピオンに勝ち越し、『Googleのネコ』以上の広い層に衝撃を与えたAlphaGO(アルファ碁)もディープラーニングの応用例だが、それだけではなく「強化学習」と言う手法で強さに磨きをかけた。
AlphaGOのベースになっているのは、DQN(Deep Q-network)と呼ばれるゲーム用の汎用AIである。ゲームソフトの入出力も結局はデジタルデータなので、入力元と出力先をプログラムであるAIにすれば、AIもゲームができることになる。
DQNは(驚くべきことに)ゲームのルールを知らない。人間と同じように、やりながらゲームのルールを覚えて、高得点を得るコツをつかんでいくように作られているのである。
AlphaGOを開発したDeepMind社は、DQNに3000万手におよぶ膨大な棋譜データを読み込ませることで、ルールと勝ち方を学ばせだ。しかし、それでも勝率はまだまだ低かった。
そこでDeepMindが実施したのが、強化学習と呼ばれる学習法である。コンピューター同士を対戦させて、さらに3000万手以上の経験を積ませることで、勝率を高めていったのである。
チェスや将棋に比べると囲碁の盤面はずっと広い。そのため、いつかはAIが碁でも人間のチャンピオンに勝つだろうが、それには10年や20年はかかると考えられていた。しかし、ディープラーニングの進展と、それに強化学習を組み合わせたことよって、早くも2016年に達成できたのだった。
「ところで、AIと言うのはどうやって開発するのでしょうか?」と神谷が尋ねた。
「はい。ディープラーニングも含めて機械学習と言うことであれば、実は神谷社長がお持ちのパソコンでも開発することができます」
「えっ! そうなんですか?」
「ええ。それこそOSがWindowsでもMacでもLinuxでも、開発環境さえあれば、機械学習のアルゴリズムは作れます。
具体的には、Rと言う統計解析言語とその開発環境、あるいはこちらは汎用言語ですがPythonの統計解析ライブラリと開発環境があればよく、しかもこれらはどちらもオープンソースなので無償で入手できます」
「無償なんですね! ちなみにアプリケーションフレームワーク(ソフトウエアを開発する際に必要な部品類をひとまとめにし、効率よく開発できるようにしたもの)はあるのですか?」
「はい。これもいくつか出ています。最近話題になっているのは、Googleが2017年2月かに無償で提供を開始したTensorflow(テンサーフロー)です。
これはGoogleの開発した、顔認識、音声認識、画像検索、リアルタイム翻訳などのライブラリ(たくさん部品類を整理整頓したもの)を、すべて統一されたインタフェースで利用できると言うことで評判になっています。自動運転のライブラリもあるようです」
ただ、実行環境となるとパソコンでは荷が重いケースが多いだろう。科学技術計算など速度が求められるケースでは、GPUアクセラレーターと言う専用の機構を備えた機械で処理することが多い。GPUとはGraphic Processing Unit(グラフィック処理ユニット)のことで、元々画像処理専門の演算装置だが、並行処理に強いためニューラルネットワークの構築にも向いている。
「現時点でのビジネスの応用例と言えば、何でしょうか?」と神谷が尋ねる。
「1つは、まだ実証実験レベルの事例が多いのですが、数年での実用化が有望視されていることとして、ビッグデータの解析によるビジネスモデルや新事業の開発ですね」
「ビッグデータを使って学習したAIを、今度はビッグデータ解析に使うと言うことですね」
「はい。ちょっとややこしいですが」といずみは笑う。
「他は?」
「これは既にかなりのビジネス事例がありますが、コンシェルジュやパーソナルアシスタント、あるいはオンラインショッピング支援など、人間をサポートする業務ですね」
例えば顧客が何らかの相談をすると、IBM Watsonなどで開発したコンシェルジュAIが、ネット情報などを蓄積したビッグデータから一般的な知識を調べながら、一方で顧客の購買履歴や好みの傾向をCRM(顧客情報管理システム)のデータベースから取得して、総合的な提案をすると言うサービスが既に存在している。
さらにPepperなどのパーソナルロボットとAIを組み合わせて、顧客サポートを行うことも既に行われている。例えば、最近東京進出して話題になった長崎の「変なホテル」では、受付業務をロボットが行っている。
「まだ全自動ではありませんが、ある程度人間の代わりをしてくれると言う事例がどんどん出てきていますね」といずみ。
「それが進むことによって、人間がAIに業務を奪われると言うことにつながりませんか?」と神谷が真剣な顔で質問した。
「それについてはAIの将来論になりますので、いったん休憩してからお話しさせてください」といずみは言った。
まとめ
いずみの目
AIの主要な活用例として人間のサポートがあると本文にありますが、そのためにはまず自然言語解析ができることが必須となります。日本で使用する場合は日本語解析が必要になりますが、そうなるとやはり日本で開発した製品に一日の長があるようです。
![]()
メールマガジン
最新のイベント情報、商品情報など、お役立ち情報をご紹介するメールマガジンをお送りしております。




