
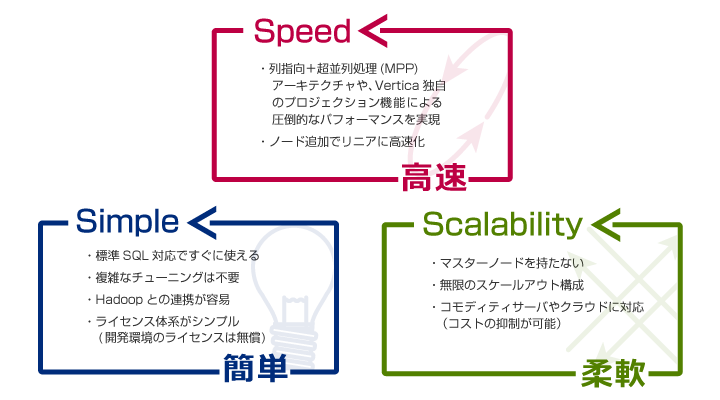
Verticaは、全世界で3,500社以上導入されている列指向型のデータベースです。大量データの分析や検索を「高速」に処理できるだけでなく、汎用的なPCサーバーを並列接続するだけで「簡単」に性能拡張することが可能です。日々データ量が増大し続けるビッグデータ分析において、コストを抑えながら「柔軟」に性能を拡張していくことも可能であり、煩雑なデータベースの管理やチューニング作業の負荷軽減などの、ビッグデータ分析における様々な課題を解決し、お客さまの意思決定のスピードアップを支援します。
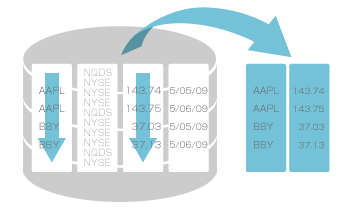
検索時に必要な列のみを読み込むため、従来のリレーショナルデータベースのように大量ディスクI/Oを必要とせず、検索を50~1,000倍高速化できます。
MPP(Massive Parallel Processing)アーキテクチャにより、業界標準のx86サーバーをクラスターに追加するだけで、容易にスケールアウトを実現できます。

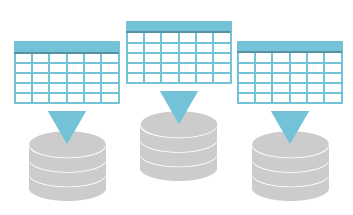
対話形式型のツール( Database Designer)を利用することで、検索に最適なデータ配置を短時間で自動的に行います。Index管理による複雑なクエリチューニングは不要です。
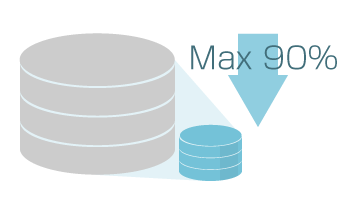
データの属性に応じた最適な圧縮アルゴリズムでストレージ容量を最大90%削減できます。
データ圧縮によって検索時のディスクI/O量が減り、高速な検索処理を実現することができます。

MapReduceを用いた膨大な構造化・非構造化および半構造化データを分析するためにHadoopとVerticaを動的に統合するHDFS Connectorが用意されています。
ANSI SQL-99準拠、JDBC/ODBC/ADO.netドライバ対応。標準的なBIツール/ETLツールをそのままご利用頂けます。更に、R言語で書かれた高度な統計アルゴリズムを高速に実行することが可能です。

11億件の取引明細データに対する分析パフォーマンスを最大9倍に強化
大規模な通信記録データ分析のリアルタイム化を実現
| OSバージョン | Linux(64bit)の下記ディストリビューション、バージョンであること RHEL6.0-6.7,7.0 / CentOS6.0-6.7,7.0 / SUSE11.0-11.0SP3 / Debian7.0-7.7 / Oracle Enterprise Linux 6 / Ubuntu12.04 LTS,14.04 LTS |
|---|---|
| LVM | OS領域を含め、非LVM構成とすること
|
| ファイルシステム | ext3またはext4であること
|
| Swap領域 | メモリサイズに関わらず、2GBとすること
|
| ディスクブロックサイズ | Verticaのカタログとデータ用に使うディスクのブロックサイズが4,096byteであること
|
| メモリ | 1つの論理プロセッサ毎に1GB以上のメモリが搭載されていること
|
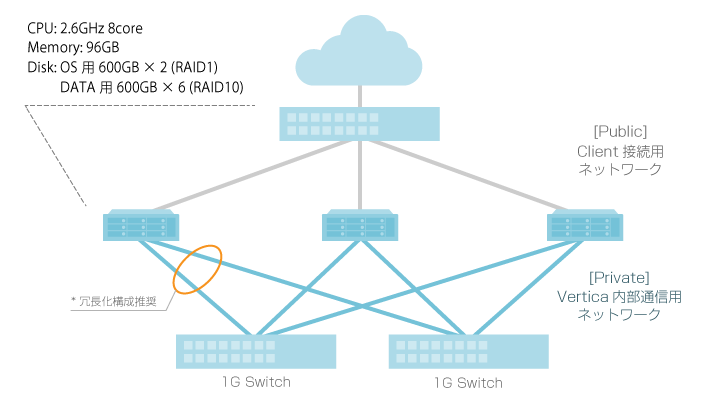
3TBのデータを処理するスモールスタート構成として、サーバ:3台、1GB Switch:2台を用いた構成例です。
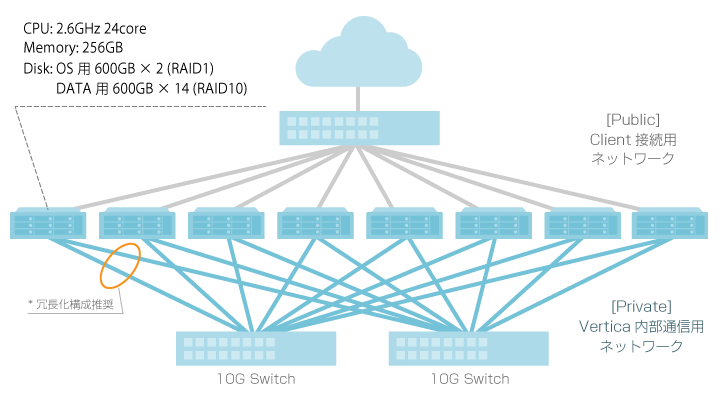
10TBのデータを処理するハイパフォーマンス構成として、サーバ:8台、10GB Switch:2台を用いた構成例です。
日立システムズでは、これまでのVertica導入における経験・ノウハウをいかし、お客さまにあったビッグデータ分析基盤の設計・構築から運用までをワンストップで支援します。
Verticaには無料のお試し版がございます。どなたでもご利用いただけますので、お気軽にお問い合わせください。
Verticaに関するご相談、資料請求、お見積りなど、お気軽にこちらからお問い合わせください。


